In building a data-driven organization, unifying disparate datasets is essential, providing a comprehensive baseline for modeling and analysis.
But joining data together to establish this baseline can be messy.
Building a Data Foundation:
It’s often been said that 80% of data-science is pre-processing your data. Too often there are small typos within datasets, varying formats for addresses, or alternate abbreviations for companies.
For example, in a recent project, I was attempting to tie population data from Wikipedia to raw COVID-19 data from John Hopkins University in order to calculate case rates . Unfortunately, many of the countries names had alternative spellings or formatting.
Some of these anomalies were trivial, like removing footnote references from the Wikipedia data using a Regex expression. However, many irregularities still existed, and this is when some additional tools can come in handy.
Using Python/FuzzyWuzzy to Cleanse and Join Messy Information
One of my favorite Python packages for such tasks is FuzzyWuzzy. While it sounds cute and adorable, it has some powerful features.
FuzzyWuzzy uses to calculate the similarity between two strings. The Levenshtein distance between two strings is the number of character substitutions, additions, or deletions needed to transform one string to the other.
FuzzyWuzzy normalizes Levenshtein distances based on the length of the strings and provides a simple API for determining the similarity between two strings on a scale of 0 (strings that don’t share a single character) to 100 (identical strings).
For example, the similarity between ‘cat’ and ‘cat’ is 100, while the similarity between ‘car’ and ‘cat’ is 66. For simple cases, you can conceptualize this as the number of shared characters; there are six characters total in ‘car’ and ‘cat’, and 4 of them are identical (‘ca-’, ‘ca-’).
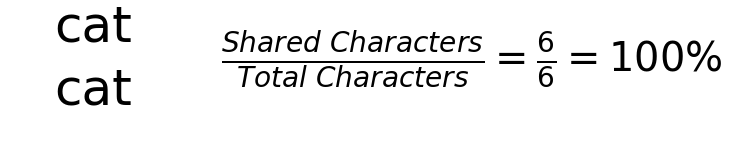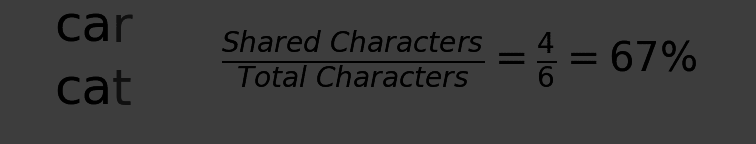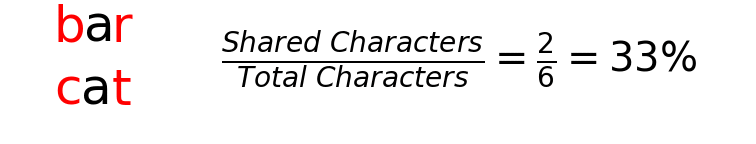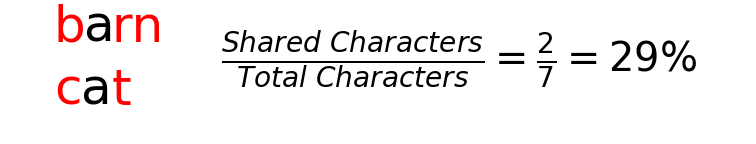
Determining Similarity Between Strings
You can calculate the similarity metric for two strings with FuzzyWuzzy as such:
from fuzzywuzzy import fuzz
fuzz.ratio("cat", "car")
What’s more powerful, is that you can also extend this functionality to find the top match(es) of those finicky join keys that aren’t aligning across your datasets. FuzzyWuzzy makes this easy with its Process module.
Here’s another example similar to their documentation page to demonstrate how:
from fuzzywuzzy import process
choices = ["cat","car", "care", "bar", "barn"]
process.extract("cat", choices, limit=4)
#Output: [('cat', 100), ('car', 67), ('care', 57), ('bar', 33)]One simple option with this is to transform unmatched keys from one dataset to those that are the closest match from the second dataset. However, as you might imagine, this could introduce just as many problems.
Using Process ExtractBests to Extend Your Range of Matches
A more robust method is to use the process.extractBests(query, choices,score_cutoff=0,limit=5) method to find the top 5 or 10 matches for a given key. These options can then be displayed to the user, who can then select the correct match, or indicate that there are no matching options. For further automation, you can also code the process to automatically transform the key if the top match is above a certain threshold.
For example, a reasonable strategy is to auto transform join keys where the top match has a fuzz similarity ratio of over 90, and fallback to a manual user-prompt for those that don’t meet this threshold.
While this process does require some manual curation, by drastically narrowing the haystack, finding the needle is a quick and reasonable task.
Here’s how you might implement such a strategy:
keys1 = df1.Key.unique()
keys2 = df2.Key.unique()
unmatched = [k for k in keys1 if k not in keys2]
threshold = 90
fuzzyMatches = {}
notFound = [] for k in unmatched:
topMatches = process.extractBests(k, keys2)
if topMatches[0][1] > threshold:
fuzzyMatches[k] = topMatches[0][0]
else:
#Prompt the User
header = "Select the number of the match. If there is no match, press any other key."
numbered = list(enumerate(topMatches))
body = "\n Country: {} \n\n".format(k)
for i, m in enumerate(topMatches):
body += """{} {} {} \n""".format(i, m[0], m[1])
idx = input(header+body)
if idx in [str(i) for i in range(10)]:
fuzzyMatches[k] = topMatches[int(idx)][0]
else:
notFound.append(k)
Conclusion:
Determining a strategy for unifying your datasets will depend on context and how you intend to use the resulting output. Some scenarios might require absolute certainty and any heuristic approaches are unacceptable. At other times, normalizing capitalization and writing a few clever regular expressions is all it takes.
My recommendation is to start with the basics and go from there. If you’re still in a bind and need some additional tools to wrangle your data, FuzzyWuzzy might be just the ticket.